Introduction
Binned scatterplots are a variation on scatterplots that can be useful when there are too many data points that are being plotted. Binned scatterplots take all data observations from the original scatterplot and place each one into exactly one group called a bin. Once every observation is in a bin, each bin will get one point on a scatterplot, reducing the amount of clutter on your plot, and potentially making trends easier to see visually.
Keep in Mind
- Bins are determined based on the conditioning variable (usually the x variable). Bin width can be determined in multiple ways. For example, you can set bin width with the goal of getting the same amount of observations into each bin. In this scenario, bins will likely all differ in width unless your data observations are equally spaced. You could also set bin width so that every bin is of equal width (and has unequal amount of observations falling into each bin).
- Once observations are placed into bins using the conditioning variable, an outcome variable (usually the y variable) is produced by aggregating all observations in the bin and using a summary statistic to obtain one single point. Possible summary statistics that can be used include mean, median or other quantiles, max/min, or count.
- The number of bins you will separate your data into is the most important decision you will likely make. There is no one way to determine this, but you will face the bias-variance trade off when selecting this parameter. The binsreg package in R, Stata, and Python has a default optimal number of bins that it calculates to make this trade off.
Also Consider
- Scatterplots
- Styling Scatterplots
- Binned scatterplots are used frequently used in Regression Discontinuity
Implementations
The binsreg package is available for R, Stata, and Python. See the package homepage.
R
It is fairly straightforward to create a basic binned scatterplot in R by hand. There is also the binsreg package for more advanced methods that includes things like automatic bandwidth selection and nonparametric fitting of the binned data; see here for another example.
For the example below I will be using this created data:
x = rnorm(mean=50, sd=50, n=10000)
y = x + rnorm(mean=0, sd=100, n=10000)
df = data.frame(x=x, y=y)
library(ggplot2)
ggplot(df, aes(x=x, y=y)) +
geom_point()
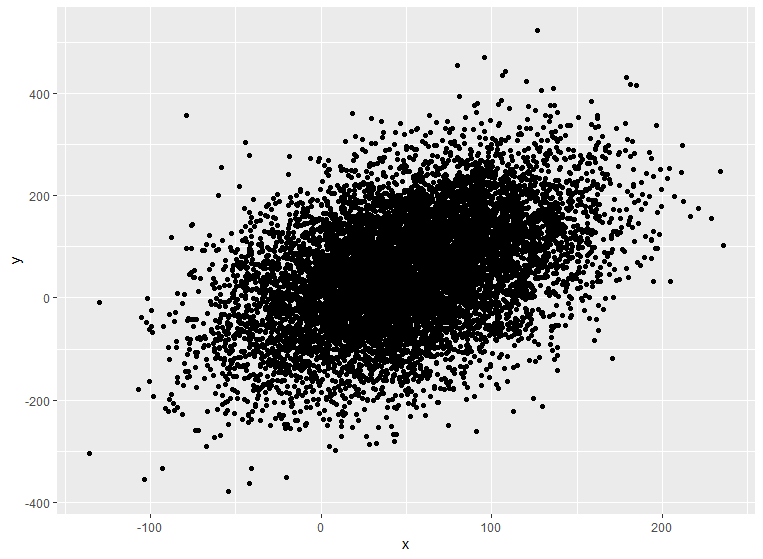
After plotting, we can see that there may be a trend, but the graph is over cluttered and not easy to interpret right away. This is when binned scatterplots are most useful.
library(dplyr)
# this will create 25 quantiles using y and assign the observations in each quantile to a separate bin
df = df %>% mutate(bin = ntile(y, n=25))
new_df = df %>% group_by(bin) %>% summarise(xmean = mean(x), ymean = mean(y)) #find the x and y mean of each bin
ggplot(new_df, aes(x=xmean, y=ymean)) +
geom_point()
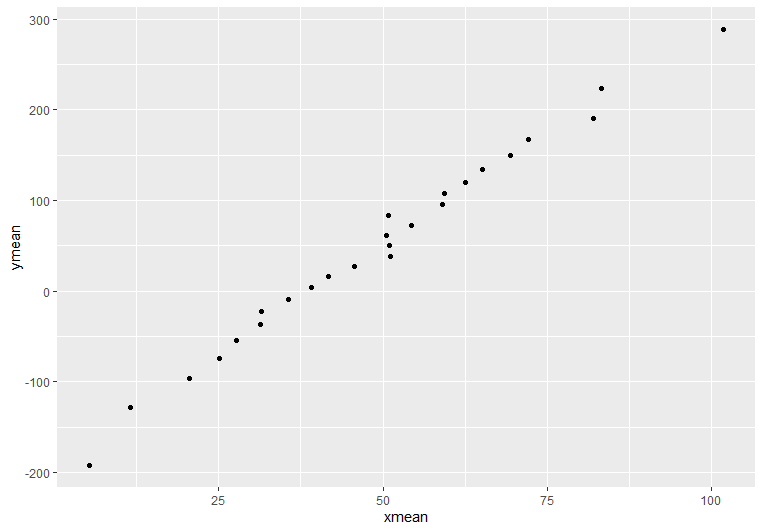
After binning and summarizing the data, we can identify the trend much easier! (but lose a sense of the very high variance)
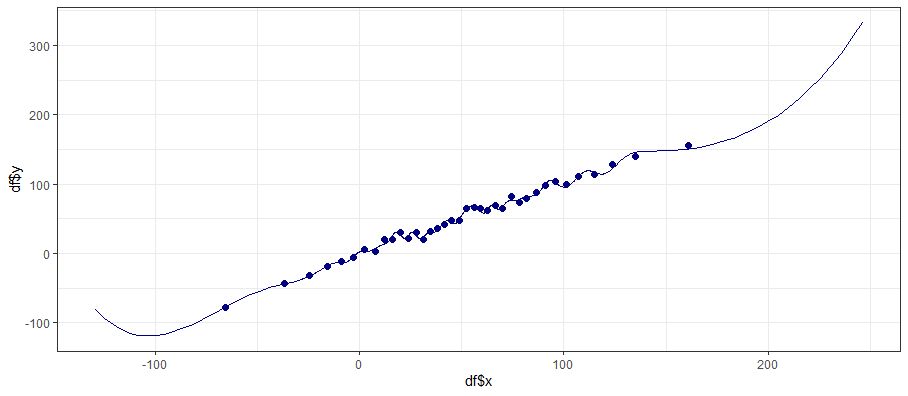
Now let’s use binsreg, which can be installed with install.packages('binsreg'). It will automatically select bins based on quantiles, allows you to apply control variables before plotting the residuals, and offers easy methods for fitting splines on top of the binned data with the line option:
binsreg(df$y, df$x, line = c(3,3))
Stata
To install binsreg in Stata Stata has the excellent user-provided package binscatter specifically for creating binned scatterplots, with plenty of options described in the help files.
* net install binsreg, from(https://raw.githubusercontent.com/nppackages/binsreg/master/stata) replace
* Create some data
clear
set obs 1000
g x = rnormal()
g y = x + rnormal()
* Default binsreg will plot means of y with quantile-based bins of x, the number of bins is by default chosen optimally
* Let's make 40 bins of x, why not
* And also add a best-fit line
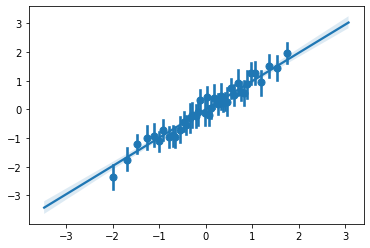
binsreg y x, nbins(40) polyreg(1)
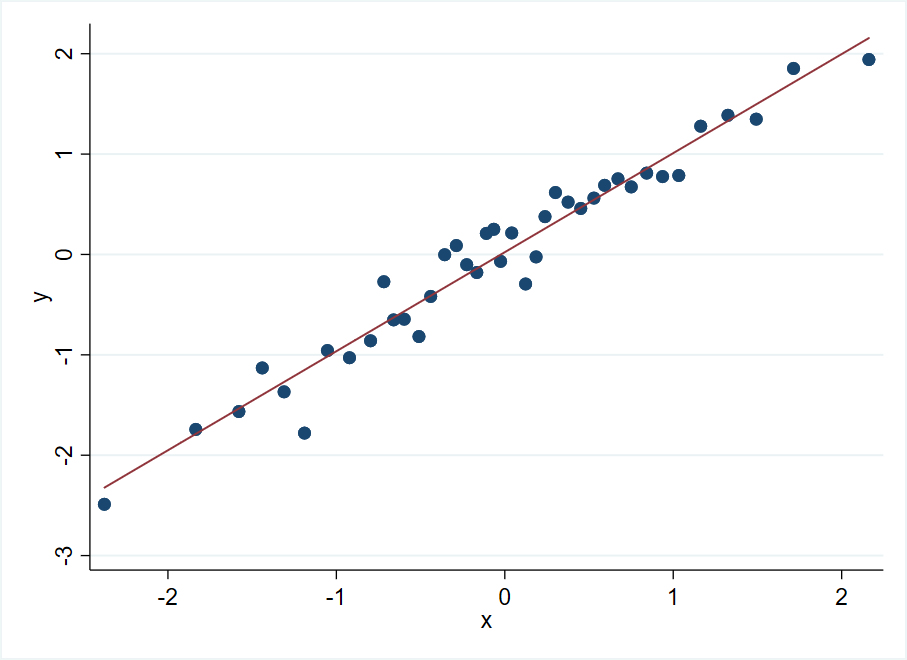
Python
The binsreg package in Python can be installed with pip. The syntax is similar to the other platforms. We can make the same plot as the Stata example above.
import numpy as np
import seaborn as sns
pip install binsreg
# Create random data
x = np.random.normal(size = 1000)
y = x + np.random.normal(size = 1000)
est = binsreg(y, x, data=data, nbins=40, polyreg=1)
est.bins_plot